
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 백준
- 자료구조 트리
- 개발상식
- 객체프로그래밍이란
- 알고리즘
- 프렌즈4블록java
- 객체프로그래밍
- 백준 1924번
- 자료구조힙
- 문자열포맷
- 코딩테스트기출
- 카카오코딩테스트
- Java heap
- 코테준비
- 카카오코테
- 카카오1차
- 자바문자열
- heap정렬
- 자바
- 힙정렬자바
- 백준 1924번 java
- heap
- java
- 공부정리
- 프로그래머스
- 프렌즈4블록
- 백준 1000번 java
- 카카오기출
- java method
- 백준 1000번
- Today
- Total
일단 시작해보는 블로그
[자료구조] 해시 Hash, 해시맵 HashMap 본문
1. 해쉬는 왜 생겼지?
가장 기본적인 자료구조인 배열의 경우 내부 인덱스를 이용하여 자료의 검색이 한번에 이루어지기 때문에 빠른 검색 속도를 보이는 반면 데이터의 삽입, 삭제 시 많은 데이터가 밀리거나 빈자리를 채우기 위해 이동해야 하므로 많은 시간이 소요된다.
또, 연결리스트는 삽입, 삭제 시 인근 노드들의 참조값만 수정해줌으로써 빠른 처리가 가능했지만 처음노드 마지막 노드 이외의 위치에서 데이터를 삽입, 삭제할 경우나 데이터를 검색할 경우에는 해당 노드를 찾기 위하여 처음부터 순회검색을 해야하기 때문에 데이터의 수가 많아질수록 효율이 떨어질 수 밖에 없는 구조였다.
이를 극복하기 위해 제시된 방법이 해쉬(Hash)이다.
2. 해쉬의 기본 개념
해쉬는 내부적으로 배열(Hash Table)을 사용하여 데이터를 저장하기 때문에 빠른 검색 속도를 갖는다.
그리고 데이터의 삽입과 삭제 시, 기존 데이터를 밀어내거나 채우는 작업이 필요 없도록 특별한 알고리즘을 이용하여 데이터와 연관된 고유한 숫자를 만들어 낸 뒤 이를 인덱스로 사용한다.
즉, 삽입 삭제 시 데이터의 이동이 없도록 만들어진 구조.
해쉬(Hash)가 내부적으로 사용하는 배열을 Hash Table 이라고 하며 그 크기에 따라서 성능 차이가 많이 날 수 있다.
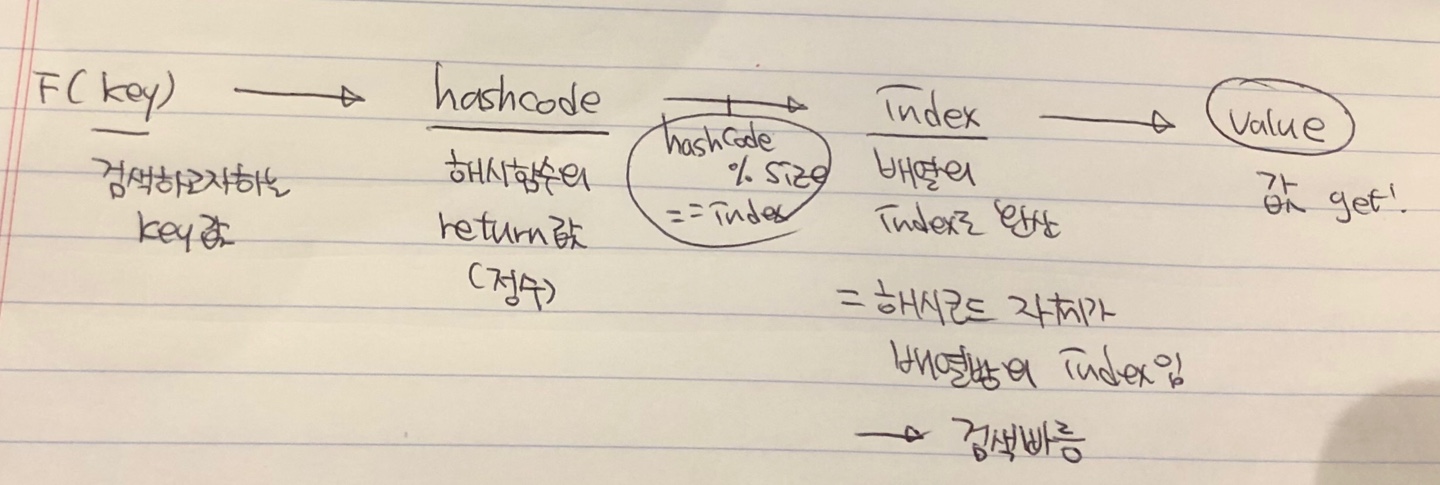
3. 해쉬(Hash) 메소드 - hashCode()
해쉬(Hash)는 Hash Table을 이용하여 데이터를 저장한다. 이때 특별한 알고리즘을 이용하여 데이터의 고유한 숫자값을 만들어 인덱스로 사용하는데 이 알고리즘을 구현한 메소드를 Hash Method 라고 하며, Hash Method에 의해 반환된 데이터 고유의 숫자 값을 Hash Code라고 한다.
Java에서는 Object 클래스의 hashCode() 라는 메소드를 이용하여 모든 객체의 Hash Code를 쉽게 구할 수 있다.
Hash Method를 구현하는 방법은 여러가지가 있지만 가장 간단한 방법으로는 나머지 연산자를 이용하는 것이다.
데이터의 고유한 hashCode를 구한 뒤 hashCode를 테이블의 크기로 나머지 연산을 한 결과를 해당 데이터의 인덱스로 사용하는 것이다.
예를 들어 'a', 'b', 'c'의 hashCode가 각각 97, 98, 99라고 하고 Hash Table의 크기가 10이라고 했을 때 테이블에 저장될 인덱스는 다음과 같다.
97 % 10 = 7
98 % 10 = 8
99 % 10 = 9
그러나, 다음의 경우를 보면
데이터 : 4, 8, 12, 16, 20, 24, 28, 32, Hash Table의 크기 : 8로 지정
4 % 8 = 4
8 % 8 = 0
12 % 8 = 4
16 % 8 = 0
20 % 8 = 4
24 % 8 = 0
28 % 8 = 4
32 % 8 = 0
데이터를 저장하기 위한 인덱스가 0번과 4번에 집중되는 것을 볼 수 있다.
이처럼 hashCode가 다르더라도 나머지 연산을 한 결과는 같을 수 있으므로 다른데이터인데 같은 인덱스로 저장되어 충돌(collision)현상이 나타날 수 있다. 이런 충돌을 최소화 하기 위한 방법으로 나머지 연산의 값이 최대한 중복되지 않도록 테이블의 크기를 소수(prime number)로 만드는 것이다.
이처럼 충돌 해결 방법으로는 개방주소법과 분리연결법 두가지가 있다.
분리 연결법
Hash Table에 연결 리스트에서 사용하는 Node 객체를 저장하는 것이다. 즉, Hash Table의 셀마다 연결 리스트를 하나씩 저장하도록 하고 충돌이 발생하는 데이터는 연결 리스트의 다음 노드로 계속 추가해 가는 것이다.
이후에 데이터를 검색할 때에는 Hash Table의 인덱스를 찾은 후 셀에 연결된 리스트를 순차적으로 탐색하며 찾으려는 hashCode와 저장된 노드의 hashCode를 비교하는 것이다.
구현 코드
package data_structure;
import java.util.LinkedList;
//해시테이블 선언
class HashTable {
//해시테이블에 저장할 데이터를 Node에 담는다.
class Node {
String key;
String value;
public Node(String key, String value){
this.key = key;
this.value = value;
}
String value(){
return value;
}
void value(String value) {
this.value = value;
}
}
LinkedList<Node>[] data;
HashTable(int size){
this.data = new LinkedList[size];
}
int getHashCode(String key){
int hashcode = 0;
for(char c : key.toCharArray()){
hashcode += c;
}
return hashcode;
}
int converToIndex(int hashcode){
return hashcode % data.length;
}
//인덱스로 배열방을 찾았는데 찾은 곳의 데이터가 여러개 존재하는 경우
Node searchKey(LinkedList<Node> list, String key){
//배열방이 null이면 null을 반환
if(list == null) return null;
for(Node node : list){
if(node.key.equals(key)){
return node;
}
}
return null;
}
void put(String key, String value){
int hashcode = getHashCode(key);
int index = converToIndex(hashcode);//배열방번호
LinkedList<Node> list = data[index];
if(list == null) {
list = new LinkedList<Node>();
data[index] = list;
}
Node node = searchKey(list, key);
if(node == null){
list.addLast(new Node(key, value));
}else {
node.value(value);
}
}
//key를 가지고 value값을 반환
String get(String key){
int hashcode = getHashCode(key);
int index = converToIndex(hashcode);
LinkedList<Node> list = data[index];
Node node = searchKey(list, key);
return node == null ? "Not found" : node.value();
}
}
public class Main {
public static void main(String[] args) {
HashTable h = new HashTable(3);
h.put("sung", "she is pretty");
h.put("jin", "she is a model");
h.put("hee", "she is an angel");
h.put("min", "she is cute");
System.out.println(h.get("sung"));
System.out.println(h.get("jin"));
System.out.println(h.get("hee"));
System.out.println(h.get("min"));
}
}
[REFERENCE]
이해가 잘 안되서 이 영상을 봤는데 한번에 이해됐다. 쵝오!.!
https://www.youtube.com/watch?v=Vi0hauJemxA
'CS > 자료구조' 카테고리의 다른 글
| [알고리즘_개념] 힙 정렬, Heap Sort (1) | 2019.08.25 |
|---|---|
| [자료구조] 힙, Heap (0) | 2019.08.25 |
| [자료구조] 트리, Tree (0) | 2019.08.25 |
| [자료구조] 큐 Queue (0) | 2019.08.21 |
| [자료구조] 종류 (0) | 2019.08.21 |
